
About the LevelUp series: At The Markup, we’re committed to doing everything we can to protect our readers from digital harm, write about the processes we develop, and share our work. We’re constantly working on improving digital security, respecting reader privacy, creating ethical and responsible user experiences, and making sure our site and tools are accessible.
At The Markup, we often do investigations focused on user privacy, or the lack thereof. So much so that we built a tool to help everyone do it. One of our primary tools is Blacklight, a scanner we first launched in 2020 to surface a website’s user-tracking technologies in real time.
But a lingering bug was hindering analysis on tracker-heavy sites that contained, on average, more than 60 ad trackers and a hundred cookies. Those websites prematurely timed out during Blacklight scans before the tool could uncover anything useful.
Join me as I recount how we caught the tricky Timeout Bug!
Gathering the Team
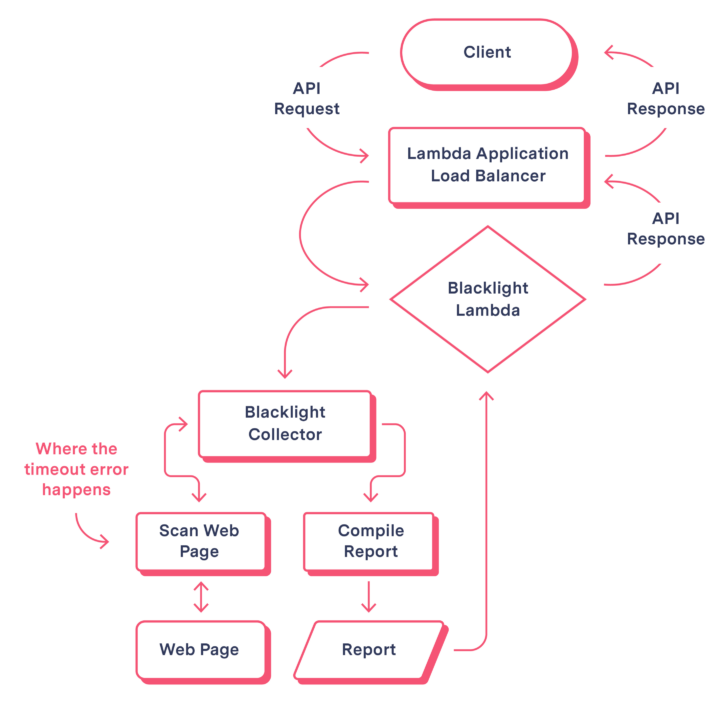
Blacklight visits websites the user is interested in, gathers tracking clues, and files reports on its findings. However, sometimes the entire scanning process would abruptly self-destruct in the middle of Blacklight’s analysis, due to an untimely timeout error. These timeout errors occur when an expected process or response doesn’t happen within a predetermined time period. In Blacklight’s case, this resulted in aborting the scan before any data could be collected, leaving the analysis incomplete.
To crack these cases, we needed to keep Blacklight on the trail longer or adapt in some other way. The answer was out there somewhere—we just had to look in the right places.
Blacklight
Announcing Three New Features for the Blacklight Privacy Inspector
The Markup’s popular tool now gives you more ways to understand how sites are tracking you
To illuminate this mystery, we assembled a team of engineers and leaders. Summer interns Jerome Paulos and I served as technical detectives, analyzing the codebase for clues. Dan Phiffer and Simon Fondrie-Teitler, The Markup’s engineers, reviewed our work and challenged our most basic assumptions.
Collaborating with my colleagues unveiled critical gaps that I had overlooked. For example, I was focused on solving timeouts for just the initial page load, missing the fact that Blacklight scans multiple pages. Jerome was pivotal in widening my perspective. He asked if I had accounted for timeouts happening at any point in the scanning process. That question made me realize I needed to standardize timeout handling across all page navigations, not just the first page. I created a helper function to gracefully handle timeouts whenever Blacklight visited a new page. This development ensured the system could collect at least partial data from later pages if timeouts occurred.Of course, robust timeout handling required much more tweaking, as we’ll see. But that simple nudge from Jerome represented a major breakthrough. This experience demonstrated firsthand that true teamwork isn’t just task delegation—it requires synthesizing insights to reveal what one person might overlook.
Tracking Down Elusive Leads
Blacklight’s core functionality relies on a tool called Puppeteer to load and interact with webpages. Puppeteer is a headless browser (not requiring graphical user interfaces) that can automate a series of web interactions, often referred to as “sessions.” Our best guess was that Puppeteer either terminated the sessions prematurely or got stuck waiting for “events” that never happened.
By default, Puppeteer times out after 30 seconds when navigating pages. For highly sophisticated websites with hundreds of trackers, 30 seconds wasn’t enough time to completely gather and log all evidence before a session ended.
We hypothesized that the timeout condition could be the culprit. But it was also possible that the timeout was just the proverbial fall guy, and something more sinister was happening behind the scenes. We methodically pursued several different leads.
Suspect #1: Default Timeout Settings
Our prime suspect was Puppeteer’s default 30-second page load timeout setting. We theorized that the duration was forcing Puppeteer to abort navigation prematurely before fully loading and executing all tracking scripts on complex pages.We gradually raised the setting from 30 to 60 seconds, then eventually 90 seconds for exceptionally tricky sites. This additional breathing room helped avoid timeouts for most standard websites we tested. However, Blacklight still could not fully load and execute third-party tracking scripts on some sites, like CNN.com or NPR.org before reaching extended timeout limits.
Meanwhile, increasing the timeout value slowed down scans for all sites, not just the outliers.
While the timer setting was clearly involved in the mystery, we lacked sufficient evidence to blame it alone.
Suspect #2: Page Load Event Rules
To test this theory, we adjusted the waitUntil property from 'networkidle2' (firing when there are no more than two network connections for at least 500 milliseconds) to 'domcontentloaded' (firing when the page first successfully loads). This generally resulted in faster page rendering, making trackable user interaction elements (e.g. form fields and buttons) available for testing sooner. However, this came at the cost of missing any resources that loaded after the 'domcontentloaded' event was fired, and as a result it was possible for us to miss catching some trackers. We could choose to be more thorough by waiting for the full page to load, including all images and scripts, by using the 'load' setting, but that option still timed out too often. And neither option completely avoided all of the dreaded timeouts.
(If you’d like to see a comparison of the four different page load options within Puppeteer, view the documentation on our public Blacklight collector repository on GitHub.)
Despite the intriguing lead, we weren’t done yet.
Suspect #3: Some Sites Are Just Too Big Not to Fail?
No matter how much we optimized timeouts and navigation, we realized there would always be exceptionally large and complex sites with failed scans due to their sheer size. These behemoth pages with endless chains of interlinked trackers and resources were just too much for Blacklight to fully analyze.

Hello World
We Asked Researchers About How They Use Blacklight. This Is What They Said
Their responses are a critical part of the feedback loop that helps us maximize the impact our tools have
Getting creative, we attempted to forcibly stop slow-loading pages after 30 seconds, while allowing the rest of each scan to proceed. Even if the page navigation timed out, we thought we could still gather partial tracking intelligence from subsequent steps.
However, abruptly halting the page navigation via Puppeteer methods such as Browser.close() and Page.evaluate(window.stop), or Chrome’s Page.StopLoading method, consistently proved unstable. Often the page ignored our stop command, kept loading anyway, and timed out. In other cases, the sudden stop commands induced errors that caused the scan to abort entirely. Here’s an example:
Protocol error (Runtime.callFunctionOn): Session closed. Most likely the page has been closed.
While a promising solution, we could not reliably freeze page loading on command.
Suspect #4: Our Own Code
While investigating the above suspects, we realized the importance of vetting our own code’s reliability. After weeks of chasing down dead-ends, I was at a loss during a debugging session with Dan. He suggested doing a fundamental check of all helper functions.
At first, I was skeptical that we could have overlooked something so basic. But walking through the code systematically revealed a subtle issue: I found a loop counter using const instead of let. This prevented a variable that counted form input elements from incrementing properly!

The error was so fundamental, yet none of us had noticed it for months. It was a good reminder that mistakes can happen, and the key is to reevaluate even base assumptions. Dan was right—that elementary catch uncovered a key reason for the timeouts.
Likewise, missing error handling allowed exceptions to bubble up. While testing forced page stops, we encountered several uncaught errors that crashed the scans. These exceptions were caused by risky utility functions we were invoking, eventually terminating the entire scan process. Adding proper error handling prevented these abrupt failures and improved the system’s overall performance.
The experience was a reminder to look inward as well as outward when debugging. Sanity-checking your own foundation is essential before pinpointing external flaws. Simple internal bugs can bring down the whole system, if left unchecked.
By first shoring up the robustness of our code, we uncovered key areas for improvement. Solid internal coding is crucial for end-to-end reliability.
We Found the Culprits
After exhausting individual suspects, the breakthrough finally came when we identified the pattern—all the vulnerabilities collectively played a role in enabling the timeouts. It was a sophisticated conspiracy!
Leveraging these insights, we devised an adaptive timing strategy that balanced speed and flexibility.
- Navigate the page with Puppeteer’s
Page.goto()method with the'networkidle2'setting; then, using a custom timeout function, limit Blacklight’s wait for the'networkidle2'event to 10 seconds - If
'networkidle2'does not fire within those 10 seconds, re-navigate the page with the'domcontentloaded'setting, which is speedier and sufficient to gather some initial intel - Include error handlers and timeout handlers in helper functions that interact with a page’s input elements
- Allow the scan to collect partial data if a timeout occurs
Meticulously engineered based on hard-won experience, this approach elegantly balanced speed, flexibility, and comprehensiveness. Initial loads were snappy when possible, but the system remained resilient when faced with complicated websites.
The result was immediately noticeable. This approach of having flexible timing requirements improved our system’s reliability without sacrificing too much scan accuracy. Some pages still occasionally time out, but much less frequently now. Blacklight can now handle scanning many websites filled with trackers without getting cut off. Thus, we solved another confounding mystery with relentless diligence and ingenious teamwork.
Looking back, this experience exemplified how open collaboration, communication, and determination can illuminate solutions when the way forward seems dark. Regular check-ins and celebrating incremental progress kept spirits high even when frustration mounted. We continually reminded each other of the greater social impact our work could have if we cracked this case. After all, tracking technologies and other background web techniques are deployed by companies who prefer their activities remain hidden.
In Dan’s words: “This bug was a true mystery, not just a puzzle. If you grind away at them long enough, these are the types of puzzles that you can eventually solve through sheer persistence.”
Resist the urge to give up early; you don’t always know how far you have come and how close you are to a breakthrough moment.



