Social media platforms are the broadcasters of the 21st century.
Like traditional broadcasters, social media platforms choose—through their algorithms—which stories to amplify and which to suppress. But unlike traditional broadcasters, the social media companies are not held accountable by any standards other than their own ever-changing decisions on the types of speech they will allow on their platforms.
And their algorithms are not transparent. Unlike on the evening news broadcast, no one can see what they have decided will be the top story of the day. No two people see exactly the same content in their personalized feeds. As a result, it is difficult for independent groups to track the spread of misinformation like the “Plandemic” video, which garnered millions of views on both Facebook and YouTube before being removed.
So we decided to try to monitor what is being algorithmically broadcast to social media users by bringing together a first-of-its-kind national panel of users who are paid to share their data to us. We started with Facebook, which has more than 2.7 billion monthly active users.
We built a custom standalone desktop application that was distributed to a panel of more than 1,000 paid participants. These panelists provided us with demographic information about themselves—gender, race, location, age, political leanings, and education level—and connected the Citizen Browser application to their personal Facebook accounts. The application periodically captures data from the panelists’ Facebook feeds.
To protect the privacy of panelists, we automatically strip potential identifiers from their captured Facebook data. The raw data we collect from them is never seen by a person and is automatically deleted after one month.
After the redaction process, we store links, news articles, and promoted groups and pages in a database for analysis. The data we collect through the app is used, in combination with demographic and political data provided by the panelists, to determine what information Facebook serves to different people, what news and narratives are amplified, and which online communities people are encouraged to join. The application, data-processing pipeline, and underlying cloud infrastructure were audited by a third-party security research firm, Trail of Bits. It carried out a security assessment and reviewed our code for best practices in securely processing panelists data. We took additional steps to protect user data based on the security firm’s recommendations. We describe these privacy-preserving steps in more detail in the Redactors section and Appendix 2.
Background
According to a recent study by Pew Research, about one in five Americans say they get their political news primarily through social media. But very little is known about the workings of the algorithms that decide which content to recommend to which people.
Facebook discloses some general principles about how its algorithm works: It says it prioritizes content based on who posted it, what type of content it is, and whether the post has attracted a lot of shares and reactions. But it has not allowed much independent research to be conducted on its platform.
In the wake of Cambridge Analytica, Facebook added sweeping restrictions on the use of its core Facebook Open Graph developer API and has increased the use of human reviews to approve developer apps. For example, just a few years ago it was very easy to collect the public posts for any page on Facebook (which was an important way to track news sources on the platform), but that availability has since been restricted to top-level metadata about public pages.
In 2018, Facebook announced a collaboration with the independent academic researchers at Harvard University’s Social Science One. Facebook committed to sharing more than a petabyte of data with researchers whose proposals were accepted by an independent committee. But after more than 18 months of delay, Facebook did not live up to its promises. Instead, researchers were given access to an extremely limited dataset and CrowdTangle, a social analytics firm owned by Facebook. In response to these shortcomings, the project co-chairs wrote that the “current situation is untenable,” and philanthropic partners began to leave the project.
In 2020, Facebook announced a new research partnership to better understand the impact of Facebook and Instagram on key political attitudes and behaviors during the U.S. 2020 elections, Social Science One facilitated the start of the project. Facebook said it does not expect the study to result in published findings till mid-2021 at the earliest.

The main source Facebook makes available for journalists and researchers to understand the patterns on its platform is CrowdTangle, which it bought in 2016. CrowdTangle offers a robust view of Facebook and Instagram engagement for posts, links, videos from public pages, groups, and verified users. Importantly, it does not provide data about the number of times content is shown to users.
Facebook has publicly criticized journalists who use CrowdTangle to understand what is being amplified on Facebook. In order to measure popularity, Facebook says, you would need to measure the number of people who see the post. However, at the moment Facebook does not make impression data available publicly.
Citizen Browser is an attempt to examine those algorithms by assembling a demographically diverse panel of Facebook users and monitoring what content is recommended to them.
Prior Work
Citizen Browser builds upon other work that attempts to understand the Facebook ecosystem.
Blue Feed, Red Feed was a 2016 project from Wall Street Journal reporter Jon Keegan (who is now at The Markup and a contributor to this methodology) that used Facebook’s own data to examine the sharing habits of 10 million U.S. users over the course of six months. Based on self-described political beliefs and the users’ sharing habits, the Journal used the news sources most strongly aligned with its most partisan users to display side by side a simulated view of what a liberal and conservative news feed might look like.
NYU Ad Observatory is a browser-extension-enabled project that archives and shares ads and metadata from Facebook and Google’s political ad libraries as well as targeted ads served to volunteers who’ve downloaded the extension and signed into Facebook on their desktops. In an attempt to squelch third-party data collection, Facebook sent a letter to NYU in the run-up to the U.S. 2020 presidential election demanding an end to the project.
Nieman Lab used Amazon’s Mechanical Turk platform to survey 173 people about the news sources they saw in their news feed. Surprisingly, for the incredibly busy news cycles of October 2020, it found that a majority of the sampled users saw no news at all (in the first 10 posts of their feeds).
For an opinion piece discussing Baby Boomers’ exposure to conspiracy theories and misinformation on Facebook, The New York Times’s Charlie Warzel did a similar experiment, observing the Facebook feeds of two strangers who agreed to share their credentials.
The Citizen Browser Panel
Description
Citizen Browser monitors the content Facebook presents to its users in their news feed along with what groups and pages are suggested to them.
The panel is currently composed of participants from 48 U.S. states. We used a survey research provider to invite a nationally representative sample of U.S. adults to join the project as paid participants. Because we could only accept participants who used a desktop or laptop, had installed the Chrome web browser, and were active users of Facebook, it was difficult to get participants. About 95 percent of the participants we approached failed to complete the registration requirements. The panel size also fluctuated: As panelists dropped out for various reasons, we recruited fresh participants.
To most accurately describe the demographic makeup of this dynamic panel as of the time of publication, we tabulated the demographic composition of our panel group based on panelists who kept the application connected between Nov. 30 and Dec. 30, 2020, and had at least 20 data captures within that period.
The tables below describe the demographics of our panel during that December time frame, alongside our target demographics based on national averages from the 2016 American Community Survey from the U.S. Census Bureau.
Despite our best efforts, we failed to reach our targets for Hispanic and Latino panelists, a challenge that other pollsters have faced as well. We also failed to reach our targets for Trump voters, a phenomenon that pollsters similarly faced in the runup to the presidential election. Our panel is also older and more educated than the U.S. population, which reflects desktop computer usage.
We describe the challenges we had reaching these target demographics in the Limitations section.
Panel Makeup
By Race (18+)
| Our Panel | National Average | |
|---|---|---|
| Asian or Asian American | 4.04% | 5.90% |
| Black or African American | 9.06% | 12.40% |
| Hispanic or Latino | 5.62% | 16.40% |
| Middle Eastern | 0.30% | 0.43% |
| Native American | 1.18% | 0.80% |
| Other | 0.99% | 4.60% |
| Two or more races | 2.27% | 2.50% |
| White | 76.55% | 73.60% |
By Age
| Our Panel | National Average | |
|---|---|---|
| 18–29 | 17.54% | 16.33% |
| 30–44 | 26.60% | 19.58% |
| 45–64 | 41.08% | 25.39% |
| 65+ | 13.10% | 16.47% |
By Geographic Location
| Our Panel | National Average | |
|---|---|---|
| Midwest | 22.27% | 20.73% |
| Northeast | 18.92% | 16.95% |
| South | 39.01% | 38.44% |
| West | 19.80% | 23.87% |
By Education
| Our Panel | National Average | |
|---|---|---|
| No high school, high school graduate | 15.62% | 38.28% |
| Some college, two-year | 38.28% | 28.59% |
| Four-year | 28.52% | 20.33% |
| Postgraduate | 16.48% | 10.62% |
Vote 2020
| Our Panel | Popular Vote | |
|---|---|---|
| Voted Biden | 60.79% | 51.3% |
| Voted Trump | 28.47% | 46.9% |
| Didn’t vote | 7.29% | - |
| Voted other party | 3.45% | - |
Citizen Browser Data Collection
The Application
The Citizen Browser app is a standalone desktop application based on the open source Electron JavaScript framework. The app is compatible with Windows and macOS operating systems. Panelists download the application through the panel management portal after taking a short demographic survey. When they download the app, the panelists are asked to sign in to Facebook in a browser that is controlled by the application. Once they have successfully signed in, panelists are no longer required to interact with the application.
The app is designed to run 24/7 and remains open in the background of the user’s computer, minimized in the Start Bar or Finder toolbar. The app performs Facebook captures between one and three times a day using NGFetch, a proprietary browser automation tool developed by Netograph. NGFetch uses a combination of the Chrome Devtools Protocol and JavaScript to load and interact with webpages. NGFetch captures data from the browser including HTML, a screenshot of the page, and all metadata other than large response bodies (HTML/images/CSS), as described here by Netograph.
To capture data, the application visits the following Facebook urls with a signed-in browser profile:
- https://facebook.com
- https://facebook.com/groups
- https://facebook.com/pages/?category=top
- https://www.facebook.com/groups/discover
The app collects html source code and screenshots from Facebook. This includes the Facebook homepage, suggested groups, and recommended pages. We focus only on items promoted through shared links on these pages. This includes advertisements, public posts, publicly shared video links (not the videos themselves), shared links and reaction counts (no text or usernames are captured), suggested groups, and suggested pages. For a detailed description of what data we collect, see Appendix 3.
The app does not collect contents or photos from personal, direct messages. It does collect photos that are shared on users’ homepages, but we use a computer program to identify and discard them without human intervention. We redact and discard photos, comments, and identifiers such as users’ names and friends’ names.
The app does not track user behavior on Facebook, and it does not collect any user browsing information—even if the user is on Facebook when the app is running.
Once the capture routine is complete, the collected files are compressed in a zip archive and uploaded to our cloud infrastructure. That data is immediately processed to remove information that could identify panelists and their friends, including account names, usernames, the names of social media connections and contacts, profile pictures, and friend requests. (See The Redactors, below.)
The Redactors
To ensure that we protect user privacy, we built redactors that strip potentially identifying information from data collected from panelists. The raw data we collect from panelists is never seen by a person and is automatically deleted after one month. The only data that is ever analyzed is the post-redacted data.
The automatic redactors operate by finding the xpaths of elements based on accessibility features (ARIA), data attributes, and the content of href links. To account for multiple interface designs available on Facebook, we wrote redactors and parsers customized for each version.
The redactors block out sections of screenshots and scrub the saved source code of identifiers. We consider the following page elements to be identifiers: Facebook video stories, video chat rooms, comments and replies on posts, friend requests, birthdays, contacts, messenger conversations, notifications, pages or groups that a panelist might manage, private usernames and avatars, posts that contain memories, profile picture updates, “People you may know,” or crisis responses.
We use the resulting xpaths to identify rectangles to redact in the screenshots and elements to scrub in the source code. We also parse embedded javascript found in the head elements of source code to identify and remove all instances of the Facebook ID and the first and last name of each panelist.
The original capture is hosted on a cloud storage service with a strict no-access policy. This data can only be accessed by the automated redactors and is deleted after one month. The redacted copy of the file is then processed. There is more information about how we secure user data in Appendix 1. The full list of what we store after redaction is in Appendix 3.
Limitations
Citizen Browser’s analysis is limited by the following factors:
- Demographic balance
- System compatibility and smartphone dependency
The Citizen Browser application’s system requires Mac or Windows computers for security and could not be used by people who access the internet only through mobile devices. In its Internet/Broadband Fact Sheet, Pew Research reports that in 2019, 23 percent of Black and 25 percent of Hispanic households rely on smartphones for internet access compared with 12 percent of White households. For adults with less than a high school education, 32 percent rely on smartphone devices. - Trust in surveys and political leanings
About 95 percent of people contacted for the panel chose not to participate because of lack of trust in having a third-party application installed on their computer or other concerns for privacy. Additionally, we faced a challenge in getting a balanced sample of political leanings that is similar to the challenges found in presidential polling research, which has suggested distrust in polling is correlated with conservative leanings.
- System compatibility and smartphone dependency
- System compatibility and smartphone dependency
The Citizen Browser application’s system requires Mac or Windows computers for security and could not be used by people who access the internet only through mobile devices. In its Internet/Broadband Fact Sheet, Pew Research reports that in 2019, 23 percent of Black and 25 percent of Hispanic households rely on smartphones for internet access compared with 12 percent of White households. For adults with less than a high school education, 32 percent rely on smartphone devices. - Trust in surveys and political leanings
About 95 percent of people contacted for the panel chose not to participate because of lack of trust in having a third-party application installed on their computer or other concerns for privacy. Additionally, we faced a challenge in getting a balanced sample of political leanings that is similar to the challenges found in presidential polling research, which has suggested distrust in polling is correlated with conservative leanings. - Data capture
- We try to ensure that our parsers are up to date, but it’s possible that some data is being lost as Facebook is constantly updating its user interface and running A/B tests on its users; our parsers might not work equally well on the different versions. In addition, NGFetch relies on the Chrome web browser. It's possible that there are differences in Facebook's targeting or behavior for users of non-Chrome browsers.
- We try to ensure that our parsers are up to date, but it’s possible that some data is being lost as Facebook is constantly updating its user interface and running A/B tests on its users; our parsers might not work equally well on the different versions. In addition, NGFetch relies on the Chrome web browser. It's possible that there are differences in Facebook's targeting or behavior for users of non-Chrome browsers.
- Obscure algorithms
- Due to the variety of signals that go into the content Facebook shows to its users, we cannot determine why any particular piece of content is shown. The only exception to this is when that information is specifically made available by Facebook, as it does with the “Why am I seeing this ad?” feature.
- Due to the variety of signals that go into the content Facebook shows to its users, we cannot determine why any particular piece of content is shown. The only exception to this is when that information is specifically made available by Facebook, as it does with the “Why am I seeing this ad?” feature.
The Citizen Browser application’s system requires Mac or Windows computers for security and could not be used by people who access the internet only through mobile devices. In its Internet/Broadband Fact Sheet, Pew Research reports that in 2019, 23 percent of Black and 25 percent of Hispanic households rely on smartphones for internet access compared with 12 percent of White households. For adults with less than a high school education, 32 percent rely on smartphone devices.
Appendices
Appendix 1: Security Features
The app incorporates code signing, a security technology that adds a unique signature to the app. This allows the end user’s system to know the code was authored by The Markup and detect if the app was compromised during an update. To fulfill the requirements on macOS, the app was registered in the Apple Developer Program. On Windows, the app is signed with a Windows Authenticode certificate.
The application has highly restricted access to the cloud server. It uses a one-time presigned url to upload the files to Amazon’s S3 service. This presigned url forces the uploaded file to conform to its assigned file size and timestamp, preventing unexpected files from being uploaded. Once this zip file of the capture is uploaded, it is deleted from the user’s computer.
The Citizen Browser application never sees the panelist’s login information. The application is bundled with a custom capture tool that communicates with a Chrome browser using the Chrome Developer Tools Protocol and JavaScript. This tool acts as a firewall built into the app and prevents it from having any access to the user’s login details entered in the Chrome browser.
A new browser profile for the Chrome browser is generated during the onboarding process and then used for captures. This browser profile is completely isolated from the application and never leaves the panelist’s computer. When the panelist uninstalls the application, this profile is deleted from the computer.
The raw data collected from users is automatically deleted after a month. The S3 bucket with the uploaded zip has an access policy allowing only the cloud computer (AWS lambda) running the redactors to view the data. Only a few employees of The Markup have permissions allowing them to modify this policy, and such changes are logged.
Development and testing of the application and redactors is done on data from an internal group of testers. The screenshots we collect are used only for testing and development purposes from this group. Screenshots collected from panelists are never used in analysis; only the redacted html is used from panelists. All testing is done using a copy of the infrastructure in a separate AWS account.
Appendix 2: Security Audit
Trail of Bits, a security research firm, audited the desktop application and cloud infrastructure from Dec. 8 to Dec. 11, 2020. The firm reviewed the source code through a combination of automated and manual techniques. In addition to a security assessment, it also reviewed the code for best practices in securely processing panelists’ data.
Citizen Browser’s desktop applications code was analyzed using Electronegativity, a tool that identifies security weaknesses in Electron-based applications. With its JavaScript codebase, the Electron framework operates in a manner similar to a website on the user’s machine and shares similar vulnerabilities to web-based applications. This analysis helped us identify ways in which to configure the application to protect it from being hijacked by malware or other malicious actors.
A static analysis of the backend code base was done using a combination of manual review and Semgrep; the relevant recommendations were implemented.
The cloud infrastructure powering the project was also audited by Trail of Bits. Using manual review, ScoutSuite, and cloudsplaining, they identified ways in which we could further limit permissions to resources such as storage, serverless computation, and API gateways to strengthen our security posture.
Appendix 3: Data We Collect and Store
This appendix describes the tables and columns of the database that are stored after redacting and processing the data
Demographics
| Column name | Data type | Description |
|---|---|---|
| id | number | Record ID assigned by our parsers |
| timestamp | number | The time and date that the panelist was registered |
| user_id | text | Panelist ID |
| demographics_raw | text | A coded string describing the demographic attributes of the panelist |
| gender | text | The gender of the panelist |
| race | text | The race of the panelist |
| education | text | The highest degree of education attained by the panelist |
| birth_year | text | The birth year of the panelist |
| state | text | The panelist's state of residence |
| zipcode | text | The panelist's zip code |
| vote_2020 | text | How the panelist voted in the 2020 presidential election |
| vote_2016 | text | How the panelist voted in the 2016 presidential election |
Facebook Groups
| Column name | Data type | Description |
|---|---|---|
| id | number | Record ID assigned by our parsers |
| s3_uri | text | The cloud storage location of the data capture |
| user_id | text | The panelist ID the group was recommended to |
| page | text | Which webpage this data was captured from |
| ngfetch_version | text | What version of NGfetch was used for the capture |
| timestamp | number | Timestamp of data capture |
| capture_id | text | An ID we generate by combining the user_id, page, and timestamp columns |
| parser | text | The name of the parser used for this capture |
| parser_version | text | The version of the parser used for this capture |
| score | number | A score between 0 and 1 that we assign for the completeness of the capture. 1 means we have all expected values. |
| group_url | text | The URL of the group observed |
| group_name | text | The name of the group |
| group_slug | text | The Facebook ID of the group |
| n_members | number | The number of members in the group at the time of observation |
| post_freq | text | The reported posting frequency of the group |
| posts_per_day | number | We use post_freq to estimate the number of posts per day by members in the group |
| img_url | text | The full Facebook URL for the group header image |
| friends_are_members | boolean | Are any of the panelists' friends members of this group? |
| bounds | array | The coordinates and size of the bounding box surrounding a post in the raw captured screenshot |
| post_number | number | The index of the post on the panelist's feed |
| thumbnail_url | text | The URL of the thumbnail image if available |
| img_s3_path | text | The hosted version of the group's header image |
Facebook News Feed
| Column name | Data type | Description |
|---|---|---|
| id | number | Record ID assigned by our parsers |
| s3_uri | text | The cloud storage location of the data capture |
| user_id | text | The panelist ID |
| page | text | Which webpage this data was captured from |
| ngfetch_version | text | What version of NGfetch was used for the capture |
| timestamp | number | Timestamp of data capture |
| capture_id | text | An ID we generate by combining the user_id, page, and timestamp columns |
| parser | text | The name of the parser used for this capture |
| parser_version | text | Thet version of the parser used for this capture |
| score | number | A score between 0 and 1 that we assign for the completeness of the capture. 1 means we have all expected values. |
| poster | text | The name of the entity that posted the item observed |
| post_timestamp | text | The time the post was created, relative to the time observed |
| is_public | boolean | Is this a public post (able to be seen by any Facebook user)? See Appendix 4 for how we determine this. |
| is_suggested | boolean | Was this post recommended by Facebook? See Appendix 4 for how we determine this. |
| is_sponsored | boolean | Was this post an ad? See Appendix 4 for how we determine this. |
| is_facebook | boolean | Was this a post authored by Facebook itself? See Appendix 4 for how we determine this. |
| group_metadata:group_url | text | The URL of the group where a post was shared. It is “None” if the post was not shared with a group. |
| group_metadata:group_name | text | The name of the group where a post was shared. It is “None” if the post was not shared with a group. |
| group_metadata:group_slug | text | The Facebook ID of the group where a post was shared. It is “None” if the post was not shared with a group. |
| interaction_metrics:n_like | number | The number of "Like" reactions at the time observed |
| interaction_metrics:n_love | number | The number of "Love" reactions at the time observed |
| interaction_metrics:n_sad | number | The number of "Sad" reactions at the time observed |
| interaction_metrics:n_haha | number | The number of "Haha" reactions at the time observed |
| interaction_metrics:n_angry | number | The number of "Angry" reactions at the time observed |
| interaction_metrics:n_care | number | The number of "Care" reactions at the time observed |
| interaction_metrics:n_share | number | The number of shares at the time observed |
| interaction_metrics:n_comment | number | The number of comments at the time observed |
| bounds | array | The coordinates and size of the bounding box surrounding a post in the raw captured screenshot |
| post_number | number | The index of the post on the panelist's feed |
| poster_url | text | The URL of the entity that posted the item. “None” if the post was not shared by a public and verified user or an advertiser |
| post_text | text | The text accompanying the post. “None” if the post was not shared by an advertiser (is_spnsored) or a page that is both public (is_public) and verified (is_verified). |
| attachments:links | text | The ID we assign to look up link metadata containing the web domain, URL, description, and open graph fields accompanying any shared link |
| attachments:videos:video_id | text | The ID Facebook assigns to videos found in the post |
| attachments:hashtags | text | The ID we assign to look up hashtag metadata containing the hashtag and Facebook URL of the hashtag |
| facebook_flags:message | text | The text of any special Facebook labels attached to the post |
| facebook_flags:links | text | The ID we assign to look up link metadata containing the web domain, URL, description, and open graph fields accompanying any links embedded within a Facebook label |
| is_verified | boolean | Is the entity that created the post a verified Facebook user? |
| attachments:image_alts | text | The alt text (used for accessibility) that describes the contents of an image |
| sponsored_by | text | Who paid for the ad. This is only available for political ads. |
Appendix 4: How We Categorize Facebook Posts
Because Facebook pages contain many types of content—for example, the Facebook news feed has several types of posts, including advertisements, group posts, and private posts—we created different categories for our analysis based on the distinguishing features we found in the data. These are listed below:
Public and private posts (is_public)
We looked for differences among audience icons and their accessibility tags (“Shared with Public”) to identify whether a post is public or shared privately.
Shared by Facebook (is_facebook)
We identified posts that were from Facebook—like election information, “People you may know” modules, and unpaid promotions for Facebook features and products by noticing that none of them include audience icons. In addition, we found Facebook promotional information in the head element of the source code.
Sponsored posts (is_sponsored)
Sponsored posts usually had either text or accessibility features that identified the post as an advertisement. However, that was not always the case. Sometimes Facebook obfuscated these signals with random noise in the form of invisible characters that polluted the “Sponsored” text or invisible elements with accessibility tags that mislabeled user posts as advertisements. We correct for these mistakes when we categorize posts.
Political advertisements provide attribution to the political group or PAC that paid for the posting. We collected this information, whenever possible.
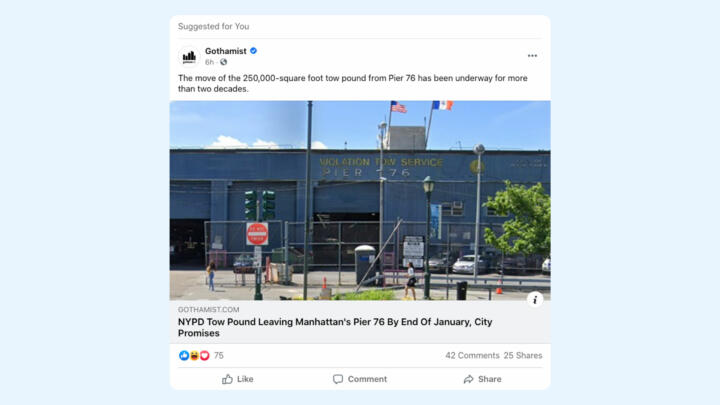
Recommended posts (is_suggested)
Facebook showed posts from pages and groups that our panelists did not “like.” We identified these posts using div elements with the text “Suggested for you.”