
About the LevelUp series: At The Markup, we’re committed to doing everything we can to protect our readers from digital harm, write about the processes we develop, and share our work. We’re constantly working on improving digital security, respecting reader privacy, creating ethical and responsible user experiences, and making sure our site and tools are accessible.
Here at The Markup we frequently combine traditional journalistic techniques with data analysis, which helps us reach conclusions grounded in statistically significant evidence. But finding and collecting enough data to draw such conclusions can be a challenge. That’s where web scraping comes in.
Web scraping is a process of automatically taking online content meant to be viewed by human users, extracting specific information from it, and then storing that information in a form that is readily usable by a computer program. For example, this could be downloading a county court’s webpage of recent rulings and turning it into a sequence of data tables, each containing the name of a court case, a list of plaintiffs, a list of defendants, the date of the ruling, and the URL for the ruling text. Because scraping is done by a computer, it can be used to harvest large quantities of information, making it popular not only among journalists, but also among academics, researchers, and advocacy groups.
Scraping has long existed in a legally gray area, so journalists and other researchers tend to approach it cautiously. At The Markup, some of our data journalists recently had questions about the legal risks involved in scraping websites hosted in the European Union. We conducted our own research to answer this question, and offer a summary of what we learned below. Our goal is to help other journalists, researchers, and advocates come up with a low-risk strategy for scraping in the EU.
A brief word about scraping in the U.S. before we begin: The legal status of scraping in the U.S. is reasonably clear in comparison to the EU. For many years, its legality was uncertain, particularly when it ran afoul of websites’ terms of service (ToS). Violating those terms seemed to potentially violate the Computer Fraud and Abuse Act (CFAA), an anti-hacking statute that made it a crime not only to break into a computer but to “exceed authorized access” to one. In April 2022, the 9th Circuit Court of Appeals clarified the situation, affirming that individuals who merely scrape websites without causing other harm cannot be prosecuted under the Act. That 9th Circuit case applied a 2021 Supreme Court decision called Van Buren v. United States, which did not involve scraping, but which held that violations of terms of service are not a crime under the CFAA.
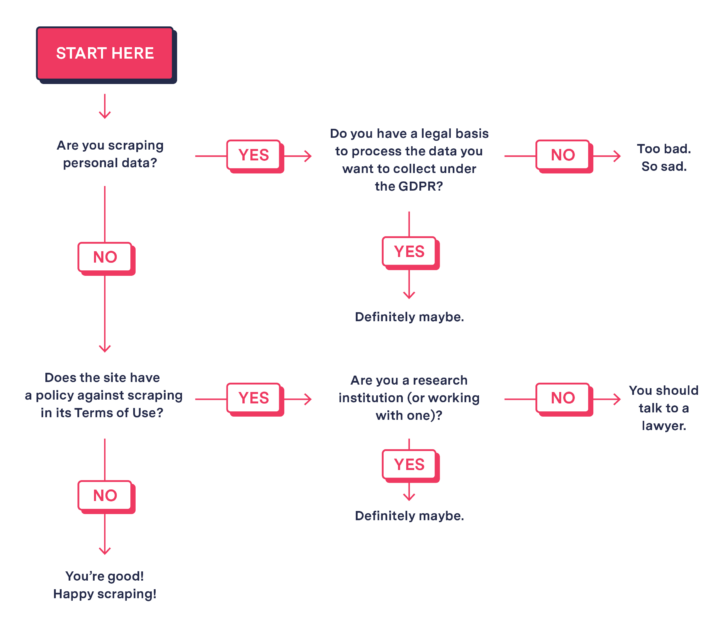
The legal status of scraping in the EU depends in large part on the nature of the data you are collecting.
Your first step in strategizing how to scrape EU-based websites should be to think carefully about what data you need for your project. The legal status of scraping in the EU depends in large part on the nature of the data you are collecting. Broadly speaking, you can think of data on the internet as falling into two categories: personal or non-personal, with different rules applying for each. Under Europe’s General Data Protection Regulation (GDPR), personal data is information that relates to an “identifiable natural person” (meaning a human, not a corporation). Names, pictures, and identification numbers like driver’s licenses are all personal data, but so are less obvious kinds of data like location information. Non-personal data, by contrast, does not relate to an identified natural person. It’s also less complicated, so we’ll start with explaining non-personal data first.
Collecting non-personal data: Four things to pay attention to

Still Loading
Dollars to Megabits, You May Be Paying 400 Times As Much As Your Neighbor for Internet Service
An investigation by The Markup found that AT&T, Verizon, EarthLink, and CenturyLink disproportionately offered lower-income and least-White neighborhoods slow internet service for the same price as speedy connections they offered in other parts of town
1. Creative and “substantial investment” rights
In our recent investigation on internet disparities, we gathered large amounts of price information for broadband internet in U.S. neighborhoods. If we had instead gathered data on EU neighborhoods, it would be considered non-personal because it does not relate to any identified individual. Therefore, the most directly relevant law is called the Database Directive, which the EU passed in 1996. The Database Directive affords copyright protection to databases that “constitute the author’s own intellectual creation.” Creativity could include how the database is organized, what kind of columns it maintains, or how it is indexed. The Directive also creates something called a sui generis (or unique) right in databases that involve “substantial investment in either the obtaining, verification or presentation of the contents,” even if there is no originality in that database. The creative and substantial investment rights are sometimes referred to collectively as database rights. It turns out that these rights are actually pretty limited in practice. It is hard to be truly creative with a database schema, and the courts set a pretty high threshold for “substantial investment.” For example, a recent decision by the Court of Justice of the European Union (basically, their Supreme Court) held that scraping only meets the substantial investment requirement if it would compete with, or otherwise endanger, the website’s ability to collect income and recoup its investment.
2. Research institutions have special permissions
The Digital Single Market Directive (which is different from the Digital Services Act and the Digital Markets Act) went into effect in 2021 and modified the Database Directive. It created safe harbors for text and data mining by research institutions or “cultural heritage organizations.” A research institution can include an entity conducting scientific research “pursuant to a public interest mission recognized by a member state.” Research institutions and cultural heritage organizations must still have “lawful access” to the data, e.g., the organization pays for a subscription, or the data is publicly available on the internet. It is unclear if journalists qualify here, even if they work for a nonprofit organization like The Markup. One possible way to address this might be to partner with a research institution, such as some universities, as public-private partnerships are allowed by the law to conduct research that aligns with one of the EU’s Framework Programmes for Research and Technological Development.
3. Companies can limit scraping in their terms of service
The limited scope of the Database Directive means that much EU data is not protected by statute and is theoretically fair game for scraping. There is a catch, however. In Ryanair Ltd v. PR Aviation BV, PR Aviation was a flight aggregation service like Kayak.com and was scraping Ryanair to show its flights in its own search results. Ryanair sued to stop this practice. The court ruled that Ryanair’s data did not qualify for protection under either copyright or a sui generis right, but that the company could limit scraping via their terms of service. Of course, as we found out in the course of building our internet service provider (ISP) pricing dataset, website operators can also employ technical measures like rate limiting to prevent scraping even when they are not exercising the aforementioned legal database rights.
Situations where scraping is limited by a platform’s terms of service are the most legally murky.
Situations where scraping is limited by a platform’s terms of service are the most legally murky. The good news is that in the EU it is not a crime to violate a website’s terms of service, which was the case in the U.S. until the Supreme Court’s Van Buren decision in 2021. If there is a ToS that prohibits scraping, the analysis does not end with “you can’t go to jail, so no big deal.” The website could bring a civil suit for either a tort or breach of contract, though they will likely have difficulty proving damages in these sorts of cases. They may also ask a court to forbid the scraping behavior. This is what happened in the Ryanair case above. If you want to scrape a website, and its ToS prohibits scraping and no exceptions apply, it is probably best to consult an attorney about your exact situation and assess your risk tolerance.
4. Don’t do cybercrime
Of course, if your scraping activity harms the website in some other way, such as visiting it so often that your scraper overloads the website, you may very well be liable under the EU’s cybercrime law, so don’t do that.
To summarize, when you scrape non-personal data from an EU source, you are potentially triggering the protections of the Database Directive, but those protections are often quite limited. Where the Directive does not apply, you may run into restrictions from the terms of service, and any anti-scraping techniques they employ to enforce those restrictions. If you partner with a research institution like a university, you may be able to circumvent the database rights, although anti-scraping tech may still pose a practical barrier. If no exception applies, there may be some risk of a civil suit, so it is best to consult a lawyer.
Collecting personal data: GDPR can turn scraping into a big compliance hassle
Of course, the 800-kilogram gorilla in the room is the GDPR. The EU’s landmark data protection law is only implicated in web scraping if you are scraping personal data. For reference, GDPR defines personal data as:

Hello World
Will Europe’s Privacy Bill of Rights Ever Truly Be Enforced?
A conversation with Tanya O’Carroll
Any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person
There are additional safeguards for “special categories” of personal data including race, religion, and sexual orientation that GDPR considers especially sensitive. Pseudonymized data, which is information with certain identifiers stripped out, is still considered identifying and therefore personal, but anonymized data is not because it does not identify an individual. However one must be careful that the data is truly anonymized because poorly anonymized data may not qualify for this exception.
Let’s say you need to scrape some data, and it contains personal data—for example, you are investigating rental listings that sometimes include the names and contact information of landlords or managers. In that case, you will be acting as a “data controller” and the provisions of GDPR governing collection and processing would apply to the personal data. First, you will need to justify the data collection as one of the six lawful bases defined by the GDPR. As a journalist or researcher, you might believe that arguing “in the public interest” would work, but this provision is mainly reserved for government agencies or private organizations that are executing the laws of a member state.
The safest bet is to collect and analyze data based on your “legitimate interest,” but even this authority is not a blank check to collect all personal data. Journalistic or nonprofit advocacy research would likely qualify as a legitimate interest, but that must be balanced against the fundamental rights of the data subject to privacy and data protection. Scraping personal data will only be legal where the interests of the data controller (you, in this case) outweigh those of the data subject. The analysis must be carefully done and formally documented, so it is best to seek a professional opinion before proceeding down this route.
If you must collect personal data, minimize and discard it as much as possible.
Once you start collecting personal data, you must adhere to the GDPR’s principles of data processing, including data minimization, reasonable data retention, and security. As a data controller, you will have certain compliance obligations for storing and handling the data, and even more obligations if you transfer it to third parties. You will also need to inform the data subjects that you are processing their data with a privacy notice, and afford them certain rights like the right of erasure or to object to processing. Finally, you may need to conduct a Data Protection Impact Assessment (DPIA) if the processing involves a “high risk” to the subject. The use of techniques like pseudonymization can help meet your compliance requirements.
The GDPR also requires each member state to implement laws that reconcile the right to privacy with freedom of expression and data processing for journalistic purposes. These national laws can vary dramatically, and there is often less guidance on how to navigate them. It can also be quite tricky to figure out which nation’s laws apply when considering where the website is incorporated, the location of the servers, and the citizenship of the data subjects. It is best to consult a lawyer if you think this exception would apply to you.
If all of this seems like a lot, that’s good because it’s supposed to be! The GDPR creates a robust framework to protect personal information, so you should only collect such data if you really need it. Going back to our rental listing example, consider whether names and contact information are necessary to collect, and if you do collect personal data incidentally, try to delete it as soon as possible.
New law will open up more government data

In 2022, the EU enacted the Data Governance Act, which will go into effect in September 2023. The law is directed at opening up government-held data, mainly by establishing “data intermediaries” and prohibiting exclusive data-sharing agreements involving the government. It seems to be a somewhat more sophisticated version of the open-data laws that some states and localities have passed in the U.S. Because it is so new, it is not yet clear how the act will impact web scraping, but if you are going to scrape a government source, it would be good to be mindful of this development.
The EU parliament is also currently considering proposals for the Data Act and for a new ePrivacy Regulation, so it is possible that the law could change in the next few years. Some of the language in the proposed Data Act would modify the sui generis right, but the details are still under discussion. As it stands now, however, web scraping of public commercial data that is not subject to copyright or privacy laws is legal in the EU. Finally, the Digital Single Market Directive that we discussed above contains a provision suggesting that even ToS may not entirely prevent researchers from scraping, but its scope is unclear and will likely need to be tested in a court.
We know. It’s complicated
The legal status of web scraping in the EU is a surprisingly complex and nuanced topic. Most of the secondary resources and much of the applicable case law are aimed at corporations that scrape the internet to further a business interest. These businesses likely have different resources and risk tolerances than most journalists, researchers, or advocates.
If you’re a journalist or researcher looking into web scraping in the EU, remember:
- Terms of service are the most likely obstacle for scraping non-personal data.
- If you must collect personal data, minimize and discard it as much as possible.
We’re assuming, too, that fellow journalists and researchers are more interested in data that would be protected by the Database Directive or GDPR, rather than text that is protected by copyright. Companies like OpenAI ingest massive amounts of text to feed their machine learning models, putting a lot of existing law to the test.
We hope this overview of EU scraping law will prove useful to data journalists and other researchers trying to gather information in the public interest. Use it to help understand the universe of possibilities in this area—but ask a lawyer if you need guidance on your particular situation—because none of this is legal advice.
Update, August 24, 2023
This story has been updated with information about national laws relating to processing personal data for journalistic purposes.



