
Hello, friends,
This week we published an investigation that was a year and a half in the making: a deep dive into PredPol, prominent crime prediction software deployed by police departments across the United States. (The company that makes it renamed itself Geolitica in March.)
Working in collaboration with the tech news outlet Gizmodo, we conducted the first-ever independent analysis of more than 5.9 million PredPol crime predictions delivered to dozens of U.S. law enforcement agencies. We found a persistent pattern of race and income disparities between the neighborhoods the software targeted for police presence and those it did not.
Critics had long suspected that PredPol’s software was reinforcing a historical pattern of over-policing Black and Latino neighborhoods. In 2016, researchers Kristian Lum and William Isaac fed drug crime data from Oakland, Calif., into PredPol’s open-source algorithm to see where it would send police. They found that it would have disproportionately targeted Black and Latino neighborhoods with patrols—unfair, considering survey data shows that people of all races use drugs at similar rates.
But until our investigation, no one had studied any of PredPol’s actual crime predictions as delivered to law enforcement agencies. We were able to see them because Dhruv Mehrotra, then a data journalist at Gizmodo, stumbled onto PredPol’s data sitting unsecured on the web.
Inspired by last summer’s wave of protests against police violence, Dhruv had built a custom search engine to search for police records across multiple jurisdictions. When he got his search engine running, the first thing he entered into it as a search term was “PredPol”—because he had been curious about the software for a long time.
Lo and behold, a smattering of PredPol records from the Los Angeles Police Department popped up. He noticed that they were in an Amazon cloud storage bucket, so he fiddled with the URLs to see if there were more documents in that bucket and hit the jackpot. There were nearly eight million predictive policing reports from PredPol sitting in the cloud without any protection. He downloaded them all.
Dhruv, who is now a data journalist at Reveal from The Center for Investigative Reporting, persuaded his editors at Gizmodo to partner with us at The Markup to analyze the data. He and The Markup’s Surya Mattu, investigative data journalist and senior data engineer, sorted through the 7.8 million PredPol crime prediction reports from 70 jurisdictions.
We decided to limit the analysis to U.S. city and county law enforcement agencies for which there was at least six months’ worth of data. This left 38 jurisdictions. We then matched the predictions to Census data to determine the demographics of the targeted areas. A complication is that each crime prediction targeted a 500-by-500-foot box, while current Census data that contains race and income information comes in neighborhoods composed of dozens of blocks (an average of 28 blocks each in our data). To confirm that wasn’t skewing the findings, Surya and Dhruv analyzed 2010 Census data for blocks that had changed less than 20 percent in the eight years in between. They found that the race disparities not only held, they also grew: In some cases predictions that appeared to target block groups that were mostly White instead targeted the blocks within them where Blacks and Latinos lived.
For a story about a prediction, a reporter would ideally want to compare the prediction to the reality—i.e., did a crime actually occur in the predicted location during the predicted time? This is a difficult task in this case because the software’s stated goal is to scare off would-be criminals by targeting patrols in the predicted areas. Therefore, if the police were patrolling during the time of those predictions, then the absence of a reported crime there would not necessarily mean the software was “wrong” that a crime would have occurred there. Except for one agency, police would not provide us any or enough of the data on how they followed predictions to examine the effects.
A comparison to true crime rates would be quite difficult anyway because much crime goes unreported to police. White and middle- and upper-income people are less likely to report crimes they suffered than Black, Latinos, and those in poverty, and the road from allegation to arrest to conviction is long.
“There’s no such thing as crime data,” Phillip Goff, co-founder of the nonprofit Center for Policing Equity, which focuses on bias in policing, told us. “There is only reported crime data. And the difference between the two is huge.”
When we reviewed arrest records for 11 jurisdictions that provided them, we found that the rates of arrests in predicted areas remained the same whether PredPol predicted a crime there in that time period or not. In other words, we did not find a strong correlation between arrests and predictions. So we settled on a disparate impact analysis: How often were different demographic groups exposed to predictions? Studies show that frequent police contact can adversely affect individuals and communities. A 2019 study published in the American Sociological Review found that increased policing in targeted hot spots in New York City under Operation Impact lowered the educational performance of Black boys from those neighborhoods. Another 2019 study found that the more times young boys are stopped by police, the more likely they are to report engaging in delinquent behavior six, 12, and 18 months later.
Our disparate impact findings were stark: PredPol’s crime predictions tracked race and income. Nearly everywhere the software was being used, the Whiter the neighborhood, the fewer predictions and the wealthier the neighborhood, the fewer predictions. (Read the full methodology here.) Many White neighborhoods had zero crime predictions, while a nearby community of color would be subjected to thousands, in a few cases more than ten thousand of them.
In a majority of 38 jurisdictions, more Blacks and Latinos lived in block groups that were most targeted, while more Whites lived in those that were least targeted
Number of jurisdictions where the proportion of each group living in the type of blocks is higher than the city overall
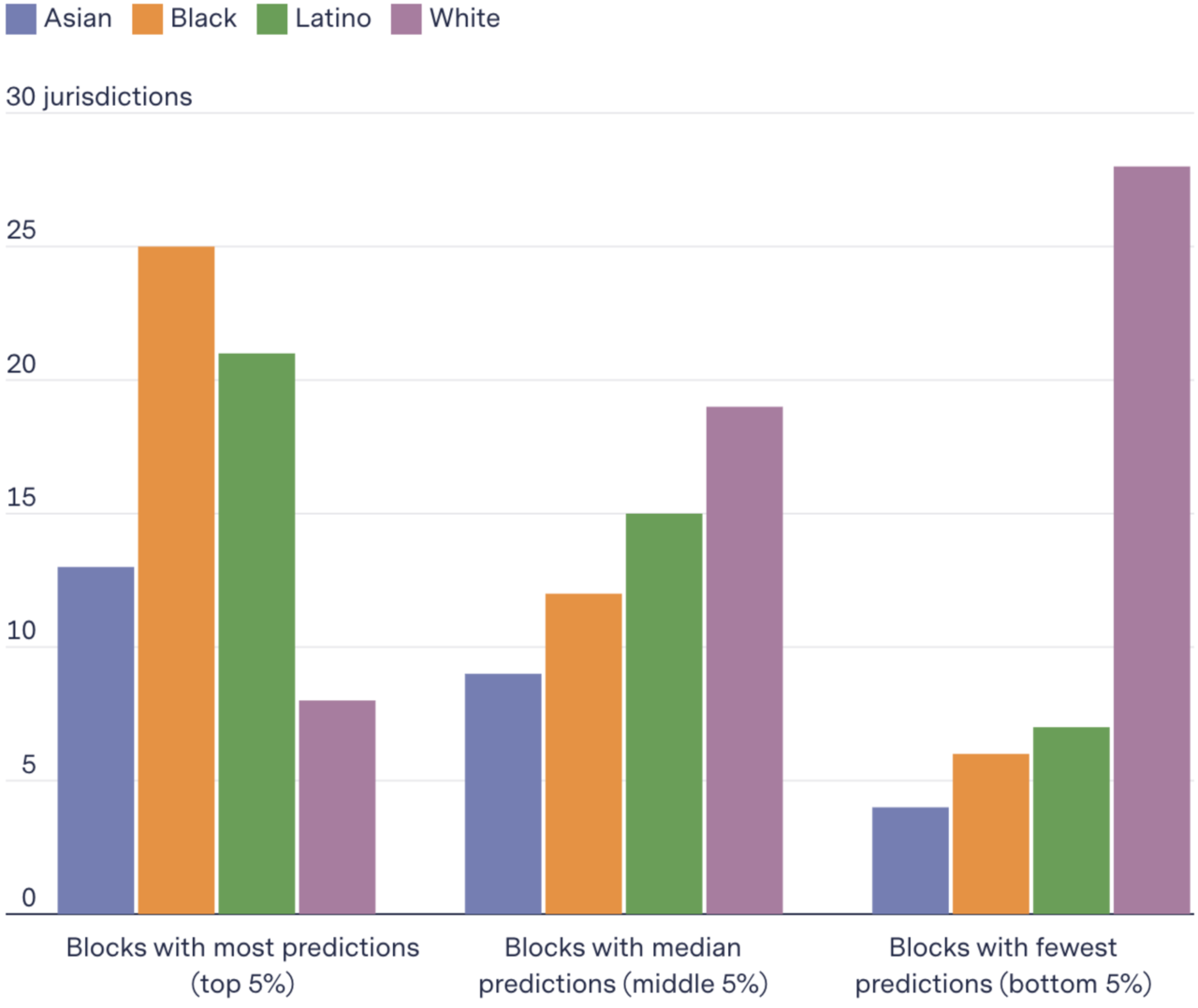
And it turned out that the disparate impact was not a secret to PredPol. We found that in 2018, PredPol’s co-founders published a paper showing that their algorithm would have targeted Black and Latino neighborhoods up to 400 percent more than White residents in Indianapolis had it been used there. The paper described how to make the algorithm more fair but “at a cost of reduced accuracy of the algorithms.” It noted, however, that the fairer algorithm was still potentially more accurate than human-created hot spot maps.
When we contacted PredPol for comment, the CEO, Brian MacDonald, told us that the company did not change the algorithm in response to the founders’ study because it would “reduce the protection provided to vulnerable neighborhoods with the highest victimization rates,” and that he did not inform clients about the paper because it “was an academic study conducted independently of PredPol.” When we asked him whether he was concerned about race and income disparities, he didn’t address those questions directly but rather said the software mirrored reported crime rates.
Still, some departments have stopped using it, many saying they didn’t find it useful. In the Chicago suburb of Elgin, Ill., police department deputy chief Adam Schuessler told Markup reporter Aaron Sankin, “I would liken it to policing bias-by-proxy.” The department said it stopped using the software in January 2020.
But he could only see what was happening in his community. Our analysis is the first independent testing of location-based crime predictions delivered to law enforcement across the country, according to Andrew Ferguson, a law professor at American University, who is a national expert on predictive policing.
“This is actually the first time anyone has done this, which is striking because people have been paying hundreds of thousands of dollars for this technology for a decade,” Ferguson said of our analysis.
We are proud to keep doing this work to hold institutions accountable for the choices they embed in their technology.
As always, thanks for reading.
Best,
Julia Angwin
Editor-in-Chief
The Markup